Transforming Database Queries with RAG and AI
|
Shivani Vichare

Introduction
In the fast-paced world of AI and data, the ability to extract meaningful insights from structured databases seamlessly is becoming a game-changer. Inspired by this challenge, I set out to explore Retrieval-Augmented Generation (RAG) and developed a robust system that combines cutting-edge AI with efficient data querying. Here’s how I tackled it:
Table Of Content
Mission
The goal was clear :
1. Automate data ingestion from AWS S3 into Frappe, creating a streamlined flow for structured information.
2. Leverage Large Language Models (LLMs) to convert natural language questions into meaningful answers from MariaDB. With this, I aimed to create a system where users irrespective of technical expertise could query databases effortlessly.
How It Works
The architecture follows a two-phase RAG approach:
1. Retrieval Phase : This is where the groundwork happens - The system intelligently queries structured datasets like SQL and fetches only.
2. Augmented Generation Phase : Here, the magic unfolds - An LLM processes the retrieved data along with the user query, generating precise, human-readable, and context-aware answers. This dual-phase approach ensures the system not only retrieves data but also understands and presents it meaningfully.

Key Scenarios and Learnings
Scenario 1: The Ideal Query
When posed with, "What is the Invoice Number for SKU ID 10009 in the Sales Register?", the system delivered a perfect response showcasing its ability to handle structured and accurate queries effectively.
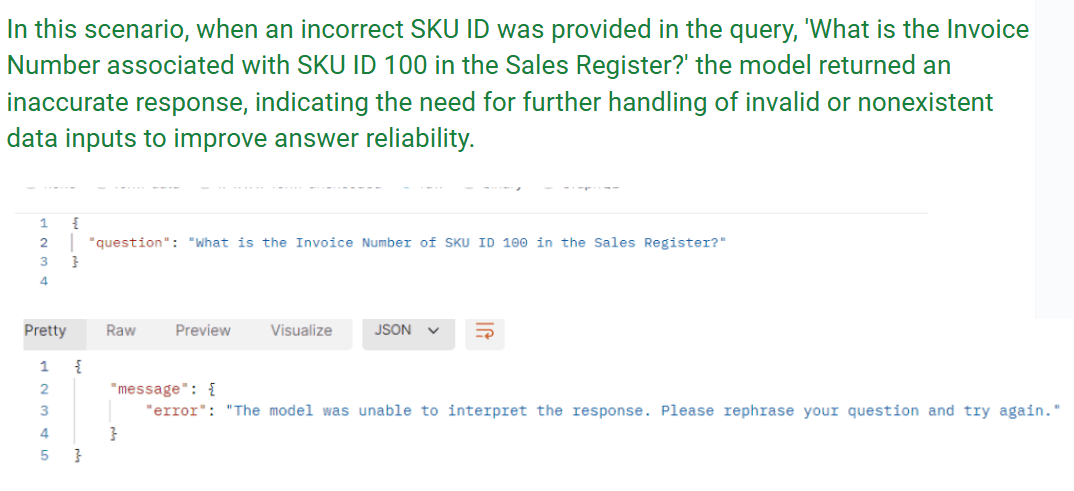
Scenario 2: The Challenging Query
However, with an invalid SKU ID (100), the system faltered, highlighting the need for:
Stronger input validation to identify incorrect data.
Enhanced error-handling mechanisms to manage edge cases.
Takeaways from the Journey
1. Automation Triumph: Automating the connection between AWS S3 and Frappe simplified data ingestion and preparation.
2. RAG in Action: The blend of retrieval and generation enabled dynamic interactions, proving the versatility of RAG architecture.
3. Growth Opportunities: This project revealed areas for improvement, such as refining the error-handling layer and enhancing LLM training for complex scenarios.
The Road Ahead
This is just the beginning! Future improvements include:
Advanced error correction for invalid or ambiguous inputs.
Scaling to include more diverse and complex datasets.
Deepening LLM capabilities to handle multi-layered queries.
The potential of RAG in reshaping enterprise-grade solutions is immense, and I’m excited to see where this journey leads.
Let’s Talk AI
This experience has opened up a new world of possibilities for simplifying data-driven workflows. Have you explored similar AI innovations? Let’s connect and share ideas!
Mission
The goal was clear :
1. Automate data ingestion from AWS S3 into Frappe, creating a streamlined flow for structured information.
2. Leverage Large Language Models (LLMs) to convert natural language questions into meaningful answers from MariaDB. With this, I aimed to create a system where users irrespective of technical expertise could query databases effortlessly.
How It Works
The architecture follows a two-phase RAG approach:
1. Retrieval Phase : This is where the groundwork happens - The system intelligently queries structured datasets like SQL and fetches only.
2. Augmented Generation Phase : Here, the magic unfolds - An LLM processes the retrieved data along with the user query, generating precise, human-readable, and context-aware answers. This dual-phase approach ensures the system not only retrieves data but also understands and presents it meaningfully.
Key Scenarios and Learnings
Scenario 1: The Ideal Query
When posed with, "What is the Invoice Number for SKU ID 10009 in the Sales Register?", the system delivered a perfect response showcasing its ability to handle structured and accurate queries effectively.
Scenario 2: The Challenging Query
However, with an invalid SKU ID (100), the system faltered, highlighting the need for:
Stronger input validation to identify incorrect data.
Enhanced error-handling mechanisms to manage edge cases.
Takeaways from the Journey
1. Automation Triumph: Automating the connection between AWS S3 and Frappe simplified data ingestion and preparation.
2. RAG in Action: The blend of retrieval and generation enabled dynamic interactions, proving the versatility of RAG architecture.
3. Growth Opportunities: This project revealed areas for improvement, such as refining the error-handling layer and enhancing LLM training for complex scenarios.
The Road Ahead
This is just the beginning! Future improvements include:
Advanced error correction for invalid or ambiguous inputs.
Scaling to include more diverse and complex datasets.
Deepening LLM capabilities to handle multi-layered queries.
The potential of RAG in reshaping enterprise-grade solutions is immense, and I’m excited to see where this journey leads.
Let’s Talk AI
This experience has opened up a new world of possibilities for simplifying data-driven workflows. Have you explored similar AI innovations? Let’s connect and share ideas!
Table Of Content
